
「GIS教程」使用Python读取dbf文件、dbf转xls、入库Postgres
发布时间: 2022-10-12
所属分类: Python、ArcGIS 学习及开发
今天遇到了一个需求,将大批量的dbf文件(存储矢量Shapefile文件的属性信息)转换为表格xls,主要探索了dbfpy库和dbfread库:尝试后发现dbfpy库效果并不好,不兼容python3.x版本,存在中文数据乱码现象;而dbfread库可以对DBF文件进行读取,删除操作,且兼容 python2.x/3.x 版本。
依赖库安装
# 官方文档链接 https://dbfread.readthedocs.io/en/latest/introduction.html
# 测试环境:python环境 3.7
pip install dbfread #安装dbfread库
# 安装pandas库(已安装请忽略,推荐使用conda来安装,结合国内的镜像源,下载速度很快)
conda install pandas
conda install xlwt
代码实现
读取dbf
from dbfread import DBF
dbf_path = r'./data-use/test.dbf' # 文件所在位置
table = DBF(dbf_path, encoding='utf-8') # 读取dbf文件
name = table.name # 名称
encoding = table.encoding # 编码
date = table.date # 创建时间
field_names = table.field_names # 字段名称列表(不包含FID)
header = table.header # 文件头(元数据)
records = table.records # 属性行
for record in records:
print(record)
table = table.deleted # 假删除
for record in table:
print(record)
dbf转xls
import dbfread as df
import pandas as pd
dbf_filename = r"./data-use/shp/test.dbf" # dbf文件
xls_filename = r"./results/test.xls" # 输出路径
data = df.DBF(dbf_filename, encoding='utf-8') # dbf编码为utf-8,如果编码错误可能会乱码
# data = df.DBF(dbf_file_name, encoding='GBK') # dbf编码为GBK,如果编码错误可能会乱码
data = pd.DataFrame(iter(data))
data.to_excel(xls_filename, index=False, encoding='gbk') # 写入表格中
print('----处理完成----')
- 效果预览
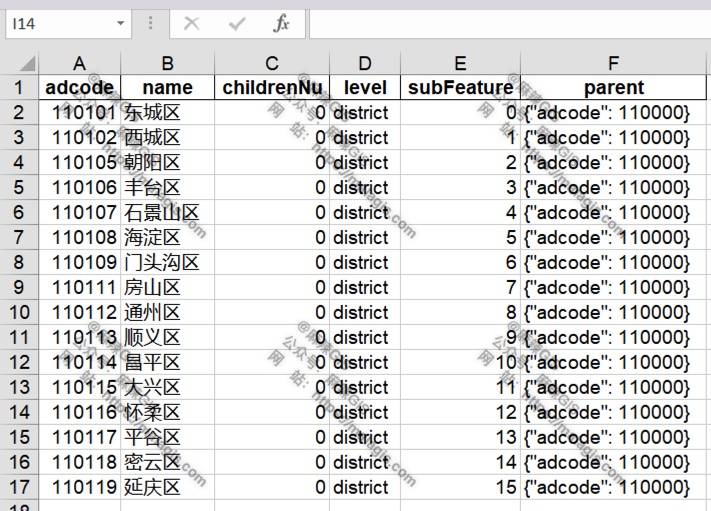
dbf转xls(批量)
这里可以转换的格式比较多样,调整下代码转xlsx、csv或者存入数据库中都是可以的哈。
import os
import pandas as pd
import dbfread as df
filter = ['.DBF', '.dbf'] # 设置过滤后的文件类型 当然可以设置多个类型
def all_path(dirname):
result = [] # 所有的文件
for maindir, subdir, file_name_list in os.walk(dirname):
print("提示:当前主目录", "1:", maindir) # 当前主目录
print("提示:当前主目录下的所有目录", "2:", subdir) # 当前主目录下的所有目录
# print("3:",file_name_list) #当前主目录下的所有文件
for filename in file_name_list:
apath = os.path.join(maindir, filename) # 合并成一个完整路径
ext = os.path.splitext(apath)[1] # 获取文件后缀 [0]获取的是除了文件名以外的内容
# 设置过滤器,过滤不符合格式的文件
if ext in filter:
result.append(apath)
return result
if __name__ == '__main__':
input_file_path = r'./data-use/shp/' # 输入路径
output_file_path = r'./results/shp/' # 输出路径
if not os.path.exists(output_file_path):
# os.mkdir创建一个,os.makedirs可以创建路径上多个
os.makedirs(output_file_path)
file_list = all_path(input_file_path)
if len(file_list) > 0:
for dbf_file_name in file_list:
try:
data = df.DBF(dbf_file_name, encoding='utf-8')
except:
# 如果报错尝试下面这一句
try:
data = df.DBF(dbf_file_name, encoding='GBK')
except:
print('该文件未进行处理', dbf_file_name)
df_data = pd.DataFrame(iter(data))
name = os.path.basename(dbf_file_name).split('.')[0]
df_data.to_excel(output_file_path + name + '.xls', index=False, encoding='gbk') # 写入表格中
print('----已处理完成----')
else:
print('----该路径下无dbf文件----')
dbf入库Postgres
'''
Python连接Postgres依赖库 conda install psycopg2
'''
import psycopg2
from dbfread import DBF
def execute_sql(conn, sql):
## 建立游标,用来执行数据库操作
cursor = conn.cursor()
## 执行SQL命令
cursor.execute(sql)
## 提交SQL命令
conn.commit()
# 关闭游标
cursor.close()
if __name__ == '__main__':
dbf_path = r'./data-use/test.dbf'
table = DBF(dbf_path, encoding='utf-8')
table_sql = 'CREATE TABLE test_area(' # 建表SQL语句
for field in table.fields:
# print(field.name) # 字段名称
table_sql += field.name
if ('N' == field.type):
table_sql += ' int,' # N代表数值型int、float or None 这里可能会报错
elif ('C' == field.type):
table_sql += ' varchar(255),' # 字符串类型
table_sql = table_sql[: -1] + ')'
## 连接到一个指定的数据库
conn = psycopg2.connect(database="db_test", user="postgres", password="postgres", host="127.0.0.1", port="5432")
# execute_sql(conn, table_sql) # 执行建表语句
insert_sql = "INSERT INTO test_area(" # 插入SQL语句
for field_name in table.field_names:
insert_sql += field_name + ','
insert_sql = insert_sql[: -1] + ') values('
for record in table:
insert_detail_sql = insert_sql
for v in list(record.values()):
if (int == type(v)):
insert_detail_sql += '{},'.format(v)
elif (str == type(v)):
insert_detail_sql += "'" + v + "',"
insert_detail_sql = insert_detail_sql[: -1] + ')'
execute_sql(conn, insert_detail_sql)
conn.close()
参考链接
- https://blog.csdn.net/jhui123456/article/details/108046201
写在最后
以上就是全部内容,推荐大家使用miniconda来管理Python环境,添加国内镜像源,下载速度很快。全部代码和示例数据已上传至码云仓库,欢迎大家下载查看。
https://gitee.com/fungiser/python-shapefile-operate/tree/develop/study-dbfread
相关阅读







声明
1.本文所分享的所有需要用户下载使用的内容(包括但不限于软件、数据、图片)来自于网络或者麻辣GIS粉丝自行分享,版权归该下载资源的合法拥有者所有,如有侵权请第一时间联系本站删除。
2.下载内容仅限个人学习使用,请切勿用作商用等其他用途,否则后果自负。
手机阅读
公众号关注
知识星球
手机阅读

最新GIS干货

私享圈子
























![[论文品鉴]反距离加权法流场矢量插值研究](https://image.malagis.com/map522.jpg?imageView2/1/w/100/h/70)









